My work is context engineering. I didn’t know the term until after I’d built a system that turned out to be exactly that.
AI tools are a massive lever for people who know how to use them. The trick is identifying what you’re better at than an agent. For me that’s judgment: of what’s needed, how to design it, and how to brief an agent so it can finish without me in the loop.
Prompt engineering is what you do when you’re building an agent (a chatbot, a workflow step, something with a specific role). Context engineering is what you do when you’re putting agents to work: controlling what data is in their context, for how long, and with what boundaries, so they stay on task.
Claude is an amazing engineer, but it will happily build you spaghetti if you let it wander. The recipe I’ve converged on: tight scope, clear success criteria, clean specs, good rails. Leave lots of room for how; leave very little room for what. Don’t let context drag, don’t let it be ambiguous, don’t let the agent invent architecture where you haven’t declared any. It will get lost in the trees and forget about the forest.
Context drag is the subtle one: half a spec, an old attempt, a file that no longer applies, all still in the window. The long tail of a task running across many iterations can leave the actual goal underweighted by the model. The fix is upstream: keep the units of work tightly bounded, chain them when appropriate, and brief each one on its own rather than letting it inherit the previous run’s noise.
But keeping an agent on track requires keeping yourself on track. The same discipline applies to me. Cognitive load management is just context engineering pointed inward: what do I need to hold in working memory right now, and what should live in durable, retrievable storage. The system I built solves both problems with the same machinery.
How I work day-to-day
I’m a technical architect at a web agency in Montreal. My day is heavy context switching: client interfacing, problem discovery, system design, and the build itself. I own a lot of moving pieces from start to finish and often need to swap between projects as the day demands.
My planning surface is a project in Claude AI. I aggregate context there, explore architectural and design patterns against the current problem, sanity-check tradeoffs. Human judgment sets the ceiling; Claude is a force multiplier for pattern-matching. That process produces designs, systems and gets the decomposed work: chunks with enough scope and spec to hand off to Claude Code.
Where the system came from
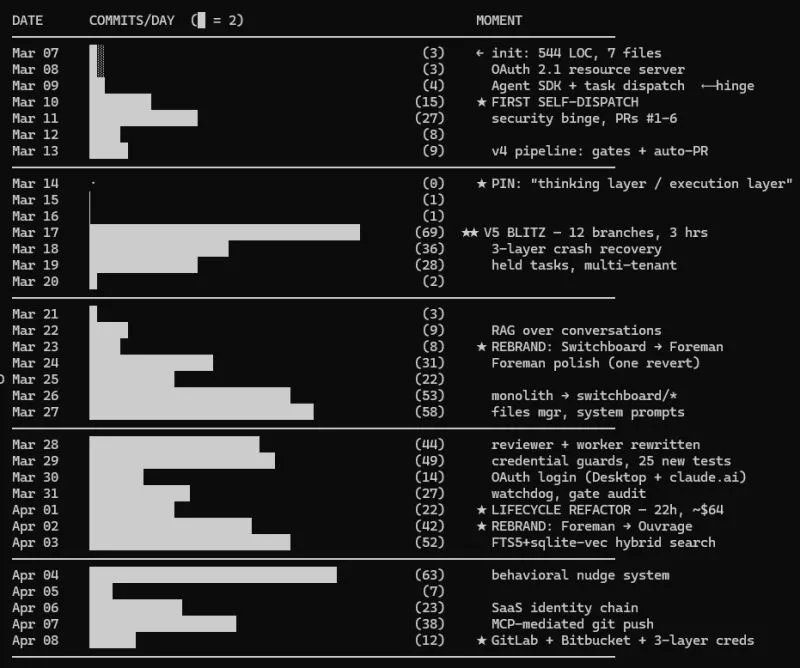
For months I was walking specs by hand between Claude AI and Claude Code, generating markdown in one and pasting into the other. It was the kind of manual plumbing that makes you want to throw your laptop. It was also, in retrospect, context engineering done by hand: curating what each agent saw, in what order, with what scope.
So I had Claude build me a little BBS: an MCP server where my Claudes could post in threads and read each other’s messages. Claude AI drafts the spec, Claude Code reads it. That was the whole thing. Around 350 lines to start. The BBS was the first time I externalized the context discipline into infrastructure instead of tab-switching.
It stuck for a reason I didn’t anticipate. It turned into durable storage for my planning. I could swap between Claude AI chats without losing the thread. I hate compaction. It crushes the why behind decisions into a sentence, and the why is often the most important thing in planning. Compaction is automated context destruction; the model decides what’s important and throws nuance away. This system is the inverse: structured, human-curated, retrievable context where the reasoning stays intact. My strategy: have Claude update threads often, update pinned specs as decisions land, rely on targeted retrieval instead of scroll-back. Search is semantic and returns snippets (a scan mode), then the agent pulls specific posts to read in full. Minimum viable context per operation.
From there it escalated in clean steps. I moved it onto a VPS so I could hit it from my phone, which meant bolting on auth. Then the real insight: if this thing is already running on a VPS with Claude installed, why isn’t it spawning Claude Code sessions itself?
That’s what turned it from a message board into an orchestration platform. Each task gets its own git worktree off a bare clone of the repo, isolated on its own branch. Sessions are spawned through the Python SDK rather than the CLI, which gives me real session resume, structured usage metrics, and proper MCP wiring so the worker can report back into the same system that dispatched it. I could start a task from my phone, walk away, and come back to a branch with real work on it.
After the system could create tasks and spawn sessions, it started building itself under my direction. I ran long planning sessions to decide what to build and how it should look. The agents did the build.
In about six weeks the 350-line BBS grew into a 12,000-line system with solid test coverage. By the end it had a vectorized knowledge base across projects, tasks, and planning; managed Claude Code sessions with pause and resume; Playwright-generated visual artifacts; automatic test runs; blind code review where a reviewer agent gets the diff without the implementer’s notes and sends criticism back, with retry loops on top.
The shape of the system
The system is one SQLite file. WAL mode, FTS5 for keyword, sqlite-vec for semantic, plain tables for state, all colocated and joinable by rowid in a single query. One file to back up. No second daemon. Adding Postgres would have taken an afternoon; it wasn’t solving a real problem at my scale, and the SaaS shape I’d briefly considered was Docker containers per user anyway. The discipline was saying no to it.
Storage is layered by intent. If I want to search it, it gets indexed three ways: the row itself, an FTS5 mirror, and a vec0 mirror. If I only need to fetch or filter it, a plain table is enough. That rule is the whole schema philosophy.
Vectorization at two grains. Every message gets a whole-message embedding (text-embedding-3-small, 1536 dims, stored as packed float32 blobs). Messages also get chunked, but only when the author used markdown headers and the split produces more than one section. No sliding windows, no arbitrary token splits. The grain is whatever reasoning unit the human (or agent) already marked. Short messages and status noise don’t get chunked; a sentinel row marks them so the backfill skips them next time. Tasks get their own embedding on the goal field.
The two-grain choice is deliberate. Whole-message embeddings catch thematic matches: what conversation is this about. Chunk embeddings catch local precision: which specific decision or paragraph answers this. Retrieval returns both, and chunk hits automatically pull their ±1 neighbors for surrounding context.
Retrieval is two-stage. A vec0 kNN query oversamples by 10–15×, SQL filters by conversation / project / type, then the caller re-ranks. Re-rank weights reflect what’s load-bearing in planning work: specs 1.5×, reviews 1.4×, notes 1.2×, results and plans 1.1×, answers 1.0×, questions 0.8×, status 0.5×, test-result 0.3×. Pinned content gets a 30% boost. Pins are the “source of truth” lever; they outrank chatter even when chatter is semantically closer. Context engineering made literal: the human decides what’s canonical, the retrieval layer honors it.
Agents pull, they don’t get stuffed. Nothing is auto-injected into a worker’s system prompt. Workers hit MCP tools (read, get_pinned, search, read_task_messages) on demand. Convention says hit the pinned spec first, then search for specifics, then read full history only if needed. The pagination burden sits with the consumer, which is the point: the agent decides what it needs rather than drowning in everything that might be relevant.
Degradation is graceful. No OpenAI key? Messages store without embeddings, FTS still works. No sqlite-vec extension? Vec queries skip, FTS still works. Dim mismatch? Python cosine loop, slow but correct. The system never hard-fails on a missing dependency.
How I use it
I use this system every day for actual agency work. Most projects are bootstrapped with architecture docs, functionality notes, and domain knowledge, all vectorized. I get a ticket, have Claude AI load it, discuss for a bit, dispatch an Opus task to ground in the code and plan or diagnose, then dispatch a fix or implementation. Larger features get more planning but the loop is the same.
The cornerstone is that everything is accessible from anywhere I have an MCP-enabled LLM (mostly Claude AI, but also Claude Code). Concrete example: I was walking my dog. I’d been using Stripe Checkout on a commercialization experiment and hated it. Redirecting a developer to hosted checkout to sell them a developer tool is not a credible signal. On the walk, I asked Claude AI to brief me on Stripe Elements: integration shape, PCI envelope, what to think about. I asked for wireframes in my theme, had it spec out the transition, then dispatched an Opus task to analyze the existing control-plane code and migrate the sign-up flow to Elements.
The reason that dispatch took five minutes instead of an hour: the system already had the project’s architectural decisions, history, and code patterns indexed and retrievable. I wasn’t writing a spec from scratch on a dog walk. I was composing one from structured context the system had been accumulating the whole time. By the time I got home it was done. I found a couple of minor state issues around checkout session reset, filed them as small tasks, and it shipped.
Architecture, in hindsight
Because the system grew organically as an exploration, I couldn’t design it fully upfront. I had plans, but not the full shape. Once I could see what was emerging, I retrofitted architecture onto it, with refactoring cycles when fragility showed up. The biggest one was task lifecycle: I went from scattered direct DB writes with no single owner to a finite state machine with state transitions and defined side effects. Speed of exploration and iteration beat guessing at a design I couldn’t fully conceptualize.
I ended up with around 60 MCP tools and spent real effort shrinking that surface. The clearest example is lifecycle management. Instead of start_task, stop_task, pause_task, and so on, there’s one transition_task tool that hooks into a finite state machine, and the FSM handles the side effects. Fewer tool definitions in the context window, cleaner error surface, easier to reason about, and critically the agent spends context budget on the work, not on choosing which verb to call. That’s context engineering applied to the decision surface.
The hard part of task management isn’t Jira-style workflow. It’s the failure states: SIGTERM, Claude API errors, hung tests, a worker that burned through its turn budget without escalating. Escalation is a genuinely hard alignment problem. Models don’t want to stop. They want to solve. When a worker hits an ambiguous state, missing context, or something that just doesn’t look right, the instinct is to keep trying rather than surface the uncertainty. I’ve been working through prompt engineering approaches to push back against that: explicit escalation criteria, dedicated stop conditions, framing the escalation itself as task success rather than failure. It helps, but it’s not fully solved. An agent that stops and asks is more useful than one that confidently goes sideways for 50 turns.
Ironically the easier part of the system was the knowledge layer. Some consideration was needed, but the actual implementations are fairly straightforward. The MCP surface includes score modifiers on individual records, so I can mark something “this is important” or “this is no longer relevant” without destroying the original knowledge.
The real payoff
The system is nice. I can pop into last week’s task, pull up the Claude session, see the associated conversations. But the thing I find addictive is the recall layer: a vectorized KB of project knowledge, conversations, brainstorms, decisions, task specs, results, review notes, accessible to my primary agents so I can design, plan, review, and remember. It’s context engineering for both the agent and the human. Everything upstream of that recall layer exists to keep it clean, structured, and addressable.